
* This piece contains many complex formulas and scores. It is written so you can fully understand it even if you skip the math and numbers, so feel free to use it just to get the general idea.
"TF-IDF" stands for Term Frequency - Inverse Document Frequency. It is a statistical method often used in information retrieval and natural language processing (NLP), and especially in search engine optimization (SEO), to measure the importance of a keyword within a document.
- TF (Term Frequency): How often a word appears within a single document
- IDF (Inverse Document Frequency): How rarely that word appears across the entire document set (scarcity)
In short, TF-IDF combines a word's frequency within a single document (TF) with its scarcity across the entire document set (IDF). The product of these two factors is the TF-IDF score.
Generally, a high TF-IDF value means a word is an important keyword that represents the document well, while a low value means the word is too general or common to characterize the document.
The Mathematical Formula for TF-IDF
TF-IDF(t,d)=TF(t,d)×IDF(t)
TF-IDF is calculated by combining term frequency (TF) and inverse document frequency (IDF), producing the formula shown above. By turning the metric into a formula and extracting a result, you can express numerically how important each word is within a document.
| Term Frequency (TF) | Inverse Document Frequency (IDF) | |
|---|---|---|
| Formula | TF(t,d)=Number of times word t appears in document d / Total number of words in document d | IDF(t)=log(N/(1+DF(t))) |
| Description | N: Total number of documents. DF(t)\text{DF}(t)DF(t): Number of documents in which word ttt appears |
Term frequency means how often word t appears within document d, and is usually calculated as the simplest raw frequency. For example, if a document has 100 words and a specific word appears 10 times, the TF is 0.1.
Inverse document frequency is used to measure how common or rare a specific word t is across all documents. The reason for using a logarithm here is to lower the score when a word appears too commonly across all documents (treating common words as less important), and to raise the score sharply the rarer a word appears.
So how does this formula apply to SEO?
Let's assume we have the following three documents.
| Document | Content (fixed at 8 words per sentence for the formula) |
|---|---|
| Document A | "SEO services are effective at increasing website traffic" |
| Document B | "Website design matters for both user experience and SEO" |
| Document C | "Combining SEO and marketing strategy aids business growth" |
Here the total number of documents (N) is 3, so N = 3. 'SEO' appears in documents A, B, and C, so DF(SEO) = 3, and 'website' appears only in documents A and B, so DF(website) = 2.
IDF(SEO)=log(3/(1+3))=log(3/4)≈−0.1249
Log is usually the natural log (ln) or the common log (log10); here we use log10. The reason a negative value appears is that the word is used so much that its importance is rated low.
| Document A | Document B | Document C | |
|---|---|---|---|
| TF score | SEO: 1 occurrence, TF = 1/8 (0.125) - website: 1 occurrence, TF = 1/8 (0.125) | SEO: 1 occurrence, TF= 1/8 (0.125) - website: 1 occurrence, TF = 1/8 (0.125) | SEO: 1 occurrence, TF= 1/8 (0.125) - website: 0 occurrences, TF = 0/8 (0) |
Conversely, TF measures usage frequency within the given document, so each item's score is tallied relatively simply as shown above. Combining these scores to calculate TF-IDF produces the following results.
| Document | Word | TF | IDF | TF-IDF |
|---|---|---|---|---|
| A | SEO | 0.125 | -0.1249 | -0.0156 |
| A | website | 0.125 | 0.0000 | 0.0000 |
| B | SEO | 0.125 | -0.1249 | -0.0156 |
| B | website | 0.125 | 0.0000 | 0.0000 |
| C | SEO | 0.125 | -0.1249 | -0.0156 |
| C | website | 0.000 | 0.0000 | 0.0000 |
You can pull the words with the highest TF-IDF scores in each document and extract them as core keywords or tags. This lets you identify which keywords are strongest on each page when planning SEO content.
Wait, the More You Repeat a Keyword, the Lower the Score?
If you were paying close attention, you've probably already noticed - and you're exactly right. This was the very point that confused me most when I first introduced TF-IDF to content analysis, and it's the part where many people analyze TF-IDF scores and conclude, 'Isn't this unrelated to SEO?'
By TF-IDF score, in the example above, the word 'SEO' becomes a 'common word' that appears too frequently across too many documents, and can therefore receive a low (even negative) score.
But this is because of the difference in purpose between the SEO perspective and the text-mining (TF-IDF) perspective.
1) TF-IDF is a Metric for "Differentiating Between Documents."
If a word "appears unusually often in this document but rarely in others," it is judged to represent this document well. In other words, the structure rewards 'scarcity,' so when a word appears in most documents, its IDF value drops, and as a result its TF-IDF also drops.
2) Googlebot, by Contrast, Values Overall Topical Consistency and Entity Recognition More Than TF-IDF
Google has evolved to recognize 'topical consistency' and 'relevance' within a document. The methods it uses for this are as follows.
(1) Entity Recognition
Example: Linking 'SEO', '검색엔진 최적화', and 'Search Engine Optimization' all as the same concept
(2) Topic Modeling
Inferring what topic a given document covers using LSI, BERT, MUM, and so on
(3) The Richness of TF Itself
If the word 'SEO' appears often and related words (e.g., keyword, Google algorithm, indexing) appear alongside it, the document is judged to be well structured around an SEO-related topic.
In other words, even if the keyword 'SEO' may score low by TF-IDF, Google can still clearly recognize that 'this site is focused on the SEO topic.'
So it is far more useful to understand TF-IDF as a metric that lets professionals working with content quantify it into data. Broken down by purpose and analytical perspective, it can be divided as follows.
| Analytical Perspective | TF-IDF Standard | Google SEO Standard |
|---|---|---|
| Purpose | Extract key terms within a document | Clearly convey the topic to search engines |
| Standard | Word scarcity (differentiation) | Topic repetition, richness of relevance |
| Recommended Approach | Common words score low | Core keywords need to be repeated sufficiently |
| Strategy | Internal content classification / recommendation | Make the topic clearly recognized by search engines |
So How Can You Apply This to SEO?
TF-IDF is not really the 'end goal itself' in SEO, but it can be used as a very powerful 'diagnostic tool' or 'strategic support tool.' Search engines do not use TF-IDF directly, but from a content manager's standpoint it is an excellent metric for understanding "which keyword plays the core role in a document" and "how differentiated my document's keywords are versus competing documents" - in other words, main-keyword concentration and internal cannibalization.
To make this easier to grasp, let's look at three situational examples along with metrics.
1. Use It for Keyword Comparison Against Competing Content
For example, suppose 238lab wrote content for the keyword 'B2B SEO strategy' and wants to know where my content falls short compared to the top 10 results on Google. You can use TF-IDF for this.
An example scenario looks like this.
(1) Crawl the top 10 pieces of content
(2) Run TF-IDF analysis on each piece
(3) Compare the top 20 TF-IDF keyword lists of my article against competing articles
| Keyword | My Content TF-IDF | Top Content Average TF-IDF | Difference |
|---|---|---|---|
| B2B | 0.089 | 0.083 | +0.006 |
| Search engine | 0.052 | 0.121 | -0.069 |
| Lead | 0.009 | 0.074 | -0.065 |
| Session retention rate | 0.000 | 0.067 | -0.067 |
Using this, you can see that among the keywords in top-ranking content, 'B2B' is mentioned at a similar level, but conversion/performance-related keywords like 'search engine', 'lead', and 'session retention rate' are lacking. You can therefore rewrite the content to reinforce these keywords.
To add a practical tip, when writing an article to rank for a specific keyword, analyzing the TF-IDF of the content already ranking for that keyword and writing around the high-scoring keywords can be a way to reduce effort.
2. Diagnose Duplicate Content and Prevent Internal Competition (Cannibalization)
For example, if 238lab's site has three pieces of content titled "WordPress SEO," "WordPress AdSense," and "WordPress AdSense SEO," they may be so similar that Google treats them as duplicate content. In that case, only one of the three carefully written pieces may end up showing in results.
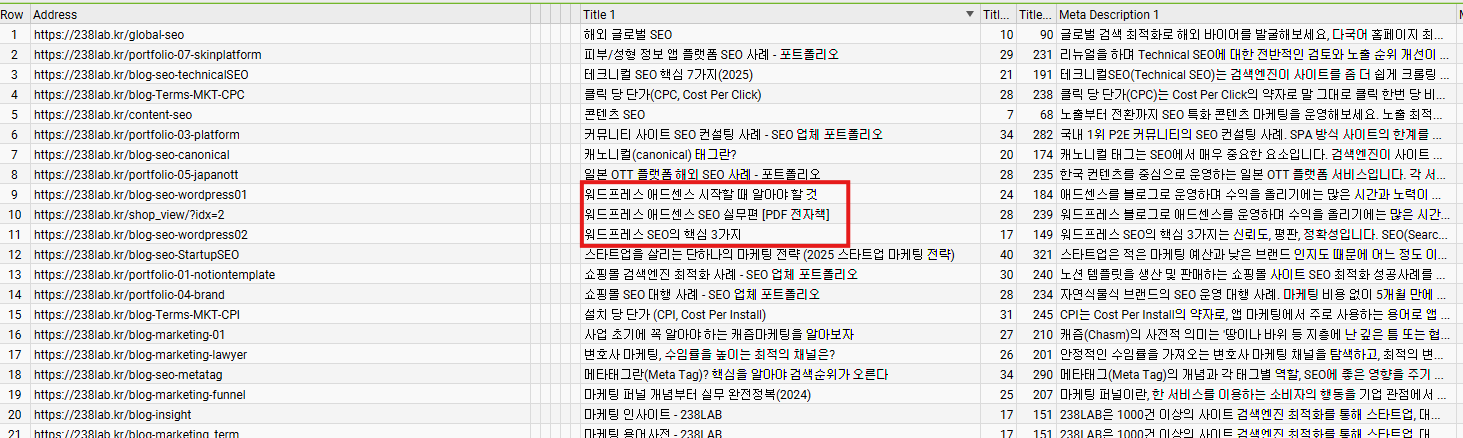
In this case, you can first extract each of the three articles' TF-IDF keywords (top 30) and judge content similarity using cosine similarity. Setting the threshold at 0.9, if similarity is 0.9 or higher the content is effectively almost identical, so you can decide to merge documents A and B, or expand document C's topic into "Practical SEO Strategy."
Alternatively, as a way to aim for top rankings with fewer resources, you can restructure the content by setting different top TF-IDF keywords to differentiate it.
3. Support for Building Content Strategy
One of the questions content writers often face is, 'Beyond the main keyword, which related keywords should I place alongside it?' Using the TF-IDF metric, you can analyze the TF-IDF of competing content that appears for a specific keyword and extract the top keywords.
If you weave the keywords extracted this way appropriately into your article, you can build well-structured content even without specialized expertise.
For example, if your target keyword is "SEO tools," TF-IDF analysis can show that "Ahrefs," "Semrush," "crawler," "backlinks," and "data visualization" are frequently mentioned. The approach is to write the article reflecting these as supporting keywords.
Collecting the top TF-IDF keywords from competing content for 'SEO tools' produces results like the following.
<Example of the top 5 keywords by TF-IDF for the 'SEO tools' keyword>
| Keyword | Average TF-IDF | Appearance Rate |
|---|---|---|
| ahrefs | 0.0412 | 18/20 |
| semrush | 0.0389 | 17/20 |
| backlinks | 0.0375 | 16/20 |
| search traffic | 0.0312 | 15/20 |
| keyword analysis | 0.0277 | 14/20 |
By building your content outline around the high-TF-IDF keywords derived this way, you can structure content without much agonizing and save a great deal of time.
Is It Even Possible to Write While Considering All of This?
Honestly, writing while perfectly considering everything is nearly impossible for one person alone.
Yet that is precisely an important point in today's SEO practice. As anyone who has actually written content for SEO knows, when writing an article to rank for a specific keyword, you go through a process of closely examining 'the search results page for that keyword,' and this process takes considerable time.
And SEO content experts actually consider the following items every time they write.
- The searcher's search intent
- Core keyword + related keywords
- The TF-IDF gap with competing content
- EEAT, structured data, UX elements
- Content freshness / length / link structure
- Whether internal content overlaps
- SERP composition (video, shopping, images, etc.)
Judging and reflecting these factors in real time while writing means you essentially have to do 'planning + analysis + writing + design + operation' all at once. Ultimately, TF-IDF-based SEO is closer to "trying to make it overly perfect will make it collapse."
Realistically, the practical way to use TF-IDF is to systematize this logic as much as possible. I think the most efficient approach is to build a strategic operational structure where the 'system' reviews, a 'person' writes the draft, and the 'system' finishes the checking and refinement.
The core logic is developing the content manager's management and operational ability - that is, building a 'structure that strategically finds and fixes shortcomings.' With the recent rapid growth of AI, even a little use of such a structure can produce higher-quality content. For those who find building this kind of structure difficult, 238lab is planning to offer TF-IDF-related tools as a web service, and we will provide them once they're ready.

About the Author
Joshua: Lead SEO Consultant
- Built a zero-cost structure generating KRW 1.2 billion in annual revenue through SEO alone - Closed a KRW 700 billion deal through SEO alone - Low-cost, high-efficiency marketing specialist Former) Marketing Lead at a financial services firm Current) Runs SEO/GEO agency 238lab Track record) Led multiple SEO consulting projects, including Korea's No.1 AI community


